In a recent study, Nicholas Boucher and Ross Anderson of Cambridge University discovered two
vulnerabilities that affect the majority of code compilers.
These kinds of flaws have an effect on software supply chains; for instance, if an attacker
successfully injects code by tricking human reviewers, the flaw is likely to be carried over into
subsequent products.
But let’s examine the method:
Extended strings: have the same effect as comments and render portions of string literals appear
to be code, invalidating string comparison.
Comment out: makes a comment appear as code so that it can be disregarded.
Early returns: execute a return statement that appears to be enclosed in a remark to get around a
function.
What follows is what?
The compilers support this special code that you cannot see; they interpret it to produce a built
application that is distinct from the one you can see in your IDE.
How does Trojan Source operate?
You or your business may have an open source project. I provide some development assistance
and submit a pull request with my contributions.
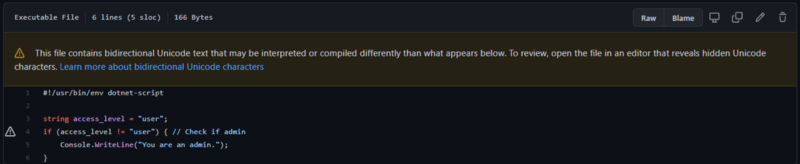
Here is an illustration:
string access_level = “user”;
if (access_level != “user”) //Check if admin
{
Console.WriteLine(“You are an admin.”);
}
This code contains Unicode characters that your IDE does not display, which creates a
vulnerability.
The text you see is altered by these characters in terms of position, order, direction, and other
factors. Thus, what you see is not the actual situation.
About how it functions, you can read here.
Having accepted or duplicated my code, your project now has the following appearance:
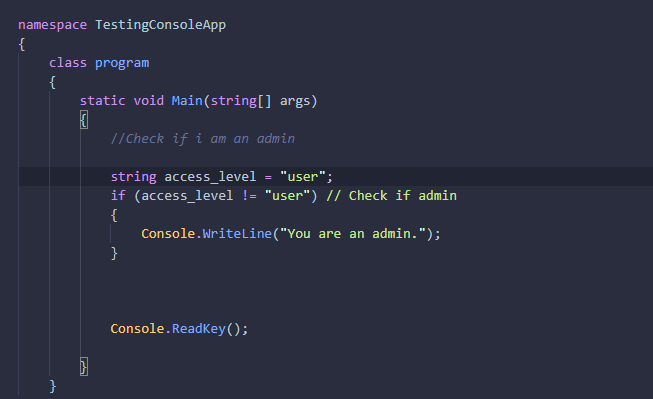
Apparently everything is fine.
Then, let’s run the Programme:
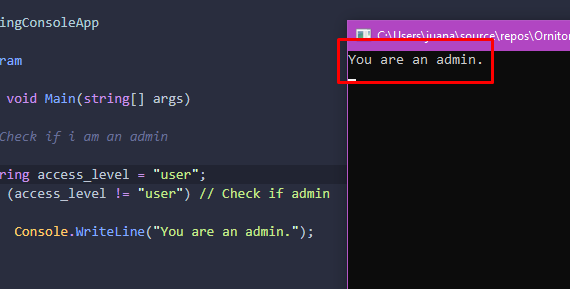
Yet… HOW?
If the access level field clearly indicates “user,”
Additionally, we are evaluating whether it differs from “user”
So…
How in the world will “user” be distinct from “user”?
because the concealed characters have been decoded before compilation.
Here is a decompiled programme (IL code) for your review:
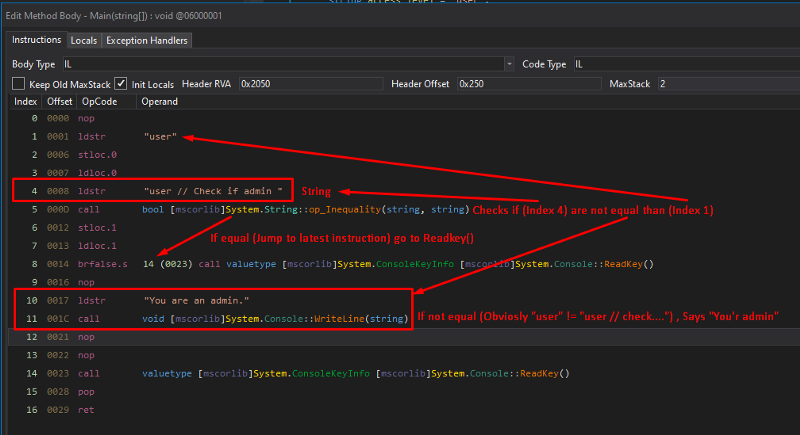
The compilation shows that the code is stating that if:
“user” ≠ “user // check if admin”
The admin’s directive will be carried out:
Console.WriteLine("You are an admin.");
Naturally, this is accomplished, and it will be carried out that we are administrators.
Let’s look at the C# output of the compilation:
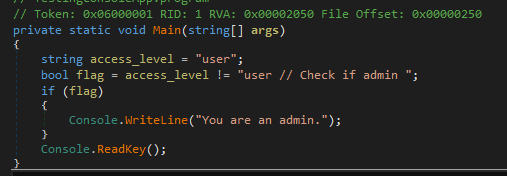
Totally distinct from the original… (However, you were unaware of this, so now I’m going to use it against you to perform admin tasks on your application even though I’m not).
This is a straightforward example, but it’s really risky because I could insert a thousand similar instructions into your production application.
How do you fix it?
Platforms like Github, fortunately, are alerting users of this:
What ought I to do?
Unterminated bidirectional control characters in string literals or comments, as well as identifiers containing deceptive mixed scripting characters, require warnings or errors from interpreters, Unicode-aware compilers, and compiler pipelines. In comments and control characters, unterminated bidirectional string literals should be expressly prohibited by language constraints. In repository interfaces and code editors, mixed-script confused characters and bidirectional control characters should be highlighted with visual warnings or symbols.
How can I determine if I’m impacted by this vulnerability?
Github’s decision to begin informing us about this is great, however What if we are already victims of it?
When considering the approaches our team might take, I considered not the greatest but the simplest.
Let’s check to see if there are any files in our source that have hidden information because ultimately the vulnerability involves the injection of hidden characters into our source code. You are most likely a.NET developer, thus we will make a small.NET tool to check this issue in our projects. .NET, YES
Solution:
Let’s first examine how to determine whether a file has any hidden characters:
UnicodeCategory.Surrogate };
var nonRenderingCategories = new UnicodeCategory[] { UnicodeCategory.Control,
UnicodeCategory.OtherNotAssigned,
UnicodeCategory.Format,
UnicodeCategory.Surrogate };
The UnicodeCategory enum that we want to find in our files is what we use. In Microsoft Docs, we have more information on what they are.
The unicode characters that may be linked to this vulnerability, in my assessment, are of type:
• Control: having a Unicode value of U+007F, either in the range of U+0000 to U+001F or U+0080 to U+009F.
• OtherNotAssigned: character for which there is no designated Unicode category.
• Format: A format character that, while not often present, has an impact on how text is laid out or how text processing functions.
• Surrogate-Low- or high-substitute characters are substitutes.
Now, all we need to do is read a.cs file (a C# source code file), which contains this vulnerability:
var nonRenderingCategories = new UnicodeCategory[] {
UnicodeCategory.Control,
UnicodeCategory.OtherNotAssigned,
UnicodeCategory.Format,
UnicodeCategory.Surrogate };
using StreamReader sr = new StreamReader(dotnetFile);
while (sr.Peek() >= 0)
{
var c = (char)sr.Read();
var category = Char.GetUnicodeCategory(c);
var isPrintable = Char.IsWhiteSpace(c) ||
!nonRenderingCategories.Contains(category);
if (!isPrintable
{
alert(dotnetFile);
issuesCount++;
break;
}
}
sr.Close();
sr.Dispose();
We will be suspicious if the file contains one of these characters.
If a file contains any of the following, it may produce false positives because the character type range I used is not precise:
- Arabic and other non-Latin alphabetic characters: أعطني 3 تصفيق
- special symbols, such as emoji
Although this solution won’t be perfect, it will alert you to potential issues so you can determine whether the file is vulnerable.The finished product is available in: TrojanSourceDetector4Dotnet
The programme allows you to check one or more .NET projects for problems with this particular vulnerability.